开源!阿里甩出首个语言世界模型,能造智能体环境
智东西
作者 | 程茜
编辑 | 心缘
智东西6月24日消息,刚刚,阿里千问大模型上新,发布首个原生语言世界模型(LWM)Qwen-AgentWorld,该模型有35B-A3B与397B-A17B两种参数规模。
该模型专门为各类AI智能体研发与训练而生。在博客中,研究人员提到,该语言世界模型的核心目的不是降成本、替代智能体的真实交互环境,而是为了增强通用智能体的能力。其可以让智能体在做动作前,先在内部模拟环境反馈再决策。
Qwen-AgentWorld两大核心亮点为:
从预训练阶段就将环境建模作为训练目标,贯穿CPT→SFT→RL全流程。此前完整训练通用基础大模型,往往会在训练结束后,才开始教AI理解环境、预判操作结果。
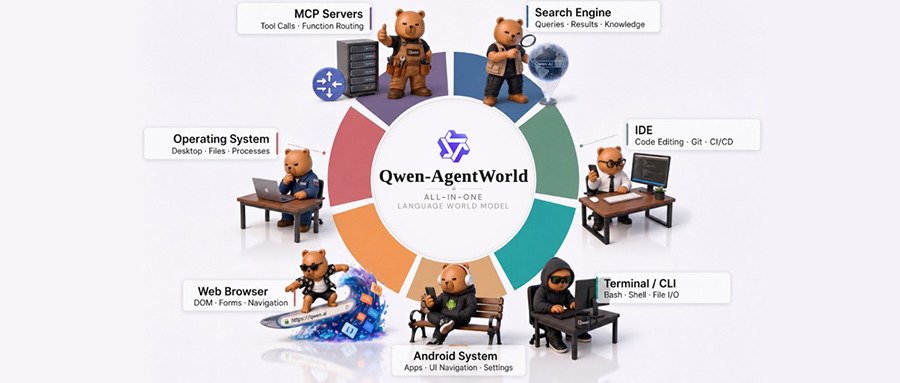
单一模型同时覆盖7类环境,包括文本类环境(MCP、Search、Terminal、SWE)与GUI类环境(Web、OS、Android),实现跨领域知识迁移。
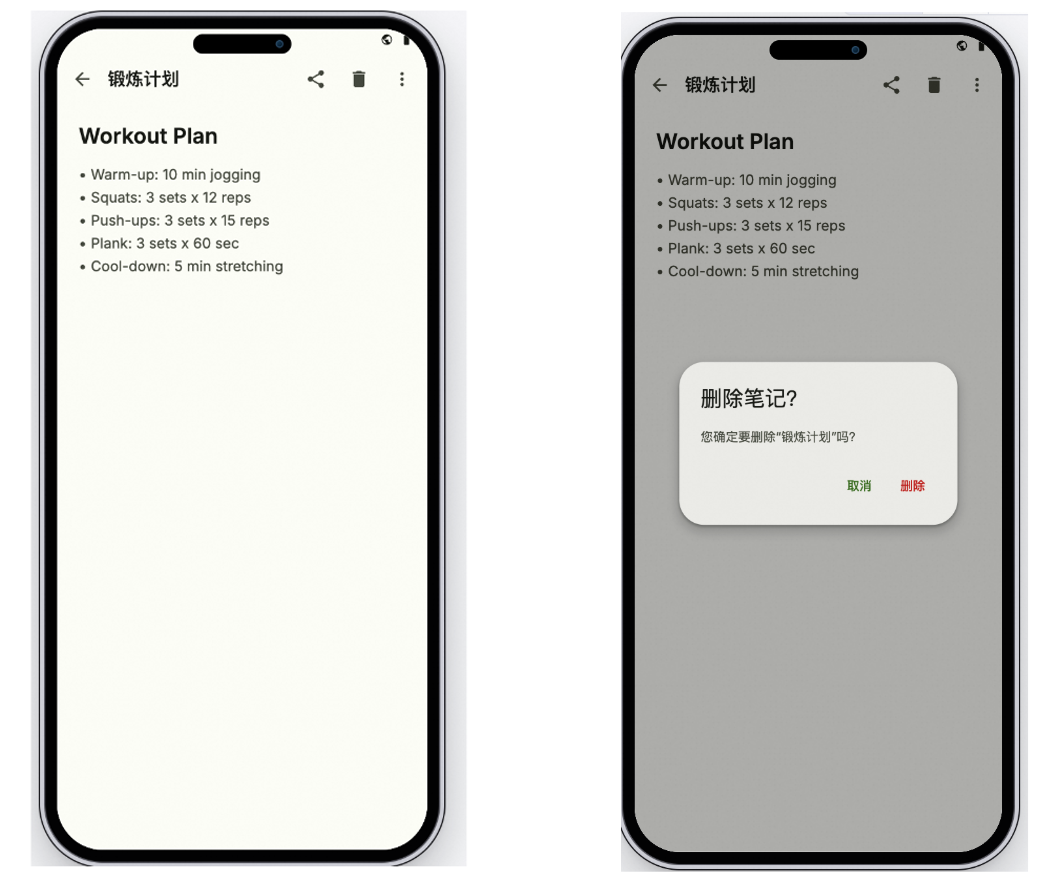
例如下图,Qwen-AgentWorld可以模拟手机系统,左侧为手机界面的初始状态,右侧为让Agent点击工具栏中的删除图标的操作预测。
研究人员在博客中提到,LWM并不是为了取代真实环境,真实环境交互始终是确保智能体行为可靠性的黄金标准,LWM提供的是一条互补路径,其具备超越真实环境的可扩展性与可控性,还有内化的世界预测能力。
此外,阿里还发布了配套的覆盖七大领域的语言世界模型评测基准AgentWorldBench。
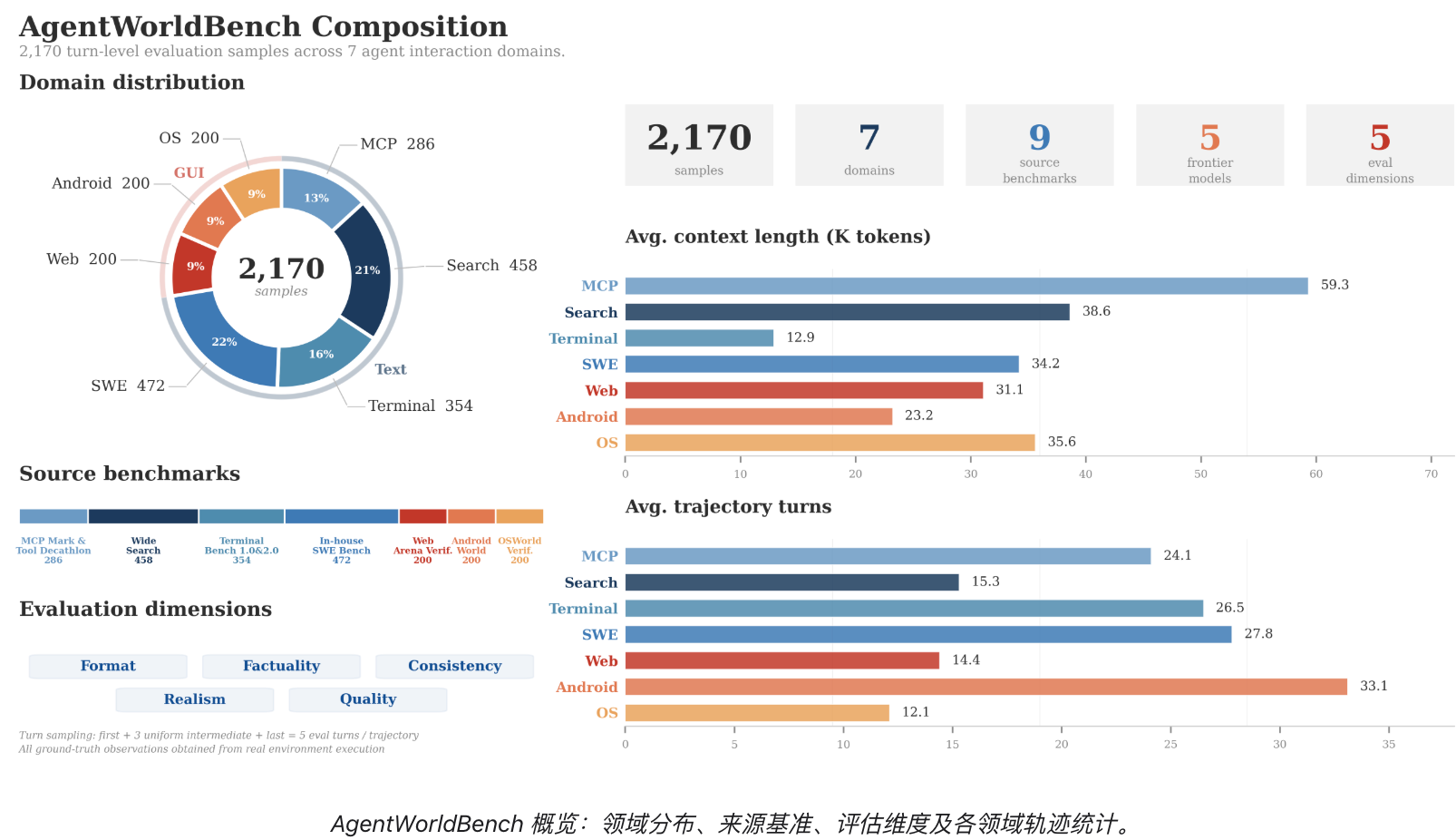
▲AgentWorldBench概览
阿里开源了Qwen-AgentWorld-35B-A3B(模型权重)和AgentWorldBench(评估基准)。
▲AgentWorld开源主页
GitHub开源地址:https://github.com/QwenLM/Qwen-AgentWorld
ModelScope开源地址:https://modelscope.cn/collections/Qwen/qwen-agentworld
Hugging Face:https://huggingface.co/collections/Qwen/qwen-agentworld
一、覆盖7类环境,支持跨领域知识迁移
Qwen-AgentWorld单一模型同时覆盖7类环境,包括文本类环境(MCP、Search、Terminal、SWE)与GUI类环境(Web、OS、Android),能实现跨领域知识迁移。
对于三个GUI领域,环境观测以可渲染代码(无障碍树XML、HTML、UI层级标记)而非像素帧的形式呈现,使得仅凭纯文本世界建模即可覆盖视觉环境。
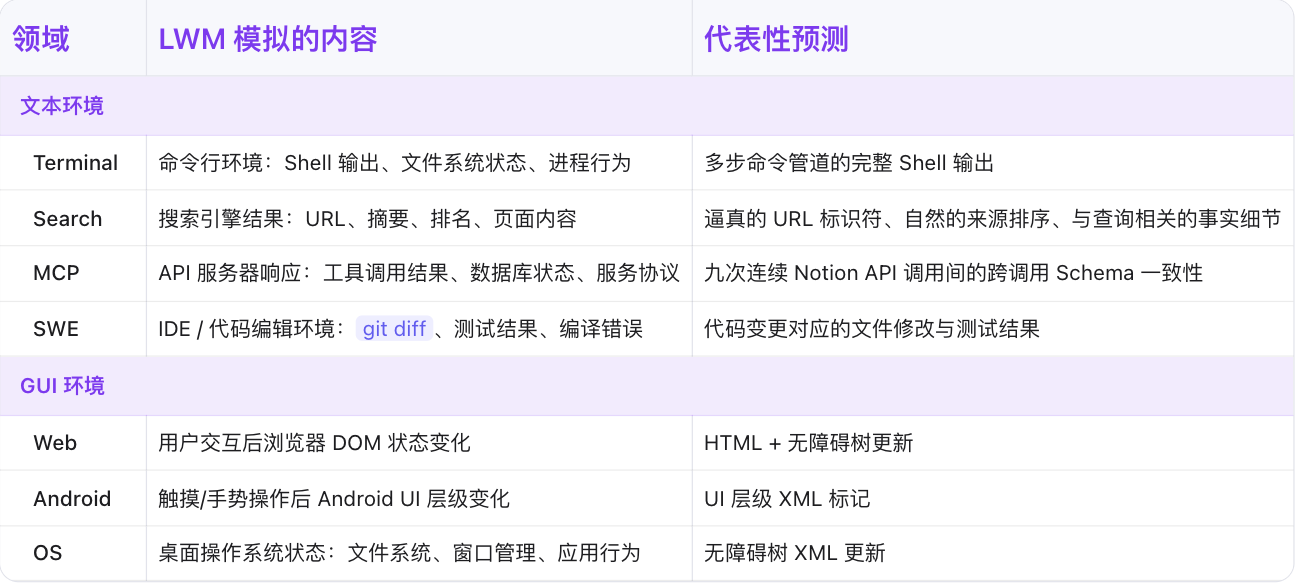
▲Qwen-AgentWorld可模拟的7类交互环境
Qwen-AgentWorld可以模拟电脑系统,例如下面左侧就是电脑初始界面,右侧为Agent从菜单栏中单击“文件”>“打印”的操作预测。
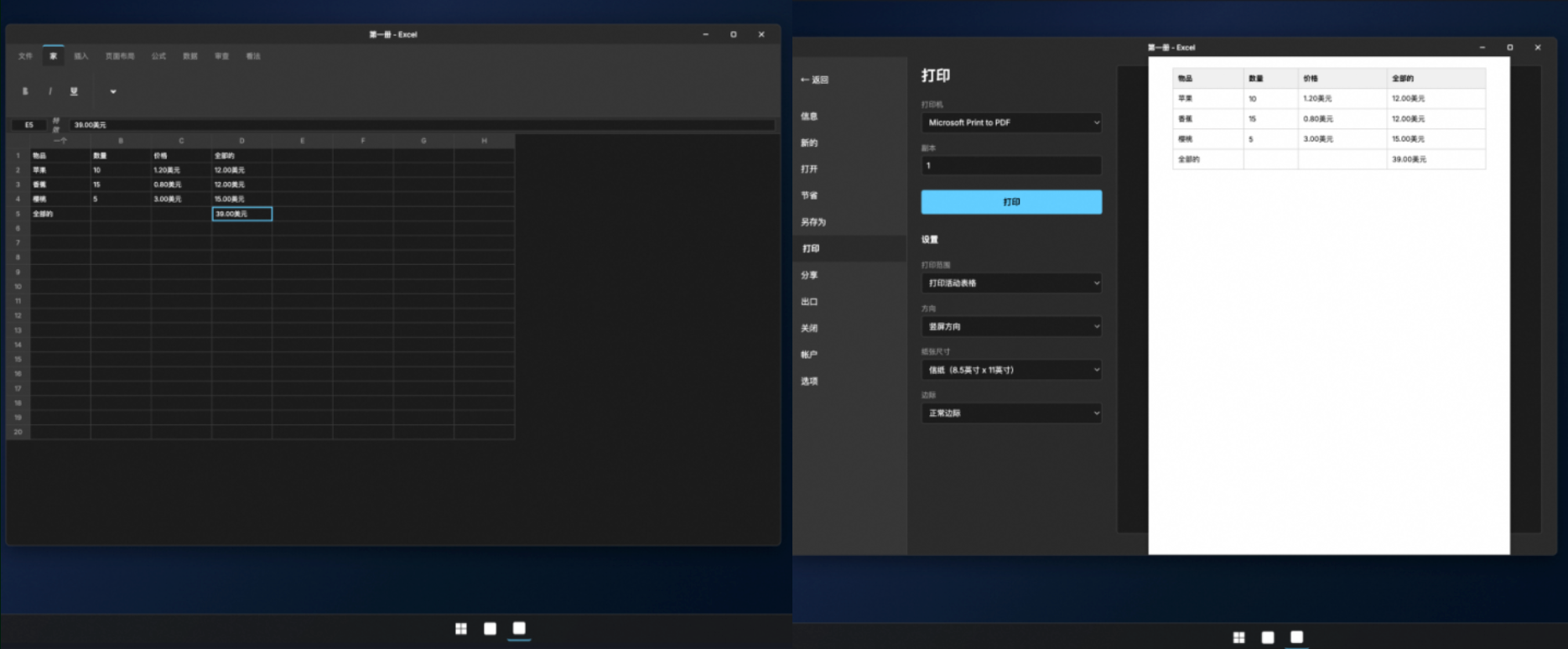
该模型还能模拟网站交互,下图左侧就是某网站的仪表盘界面,右侧为Agent点击“添加用户”按钮的操作预测。
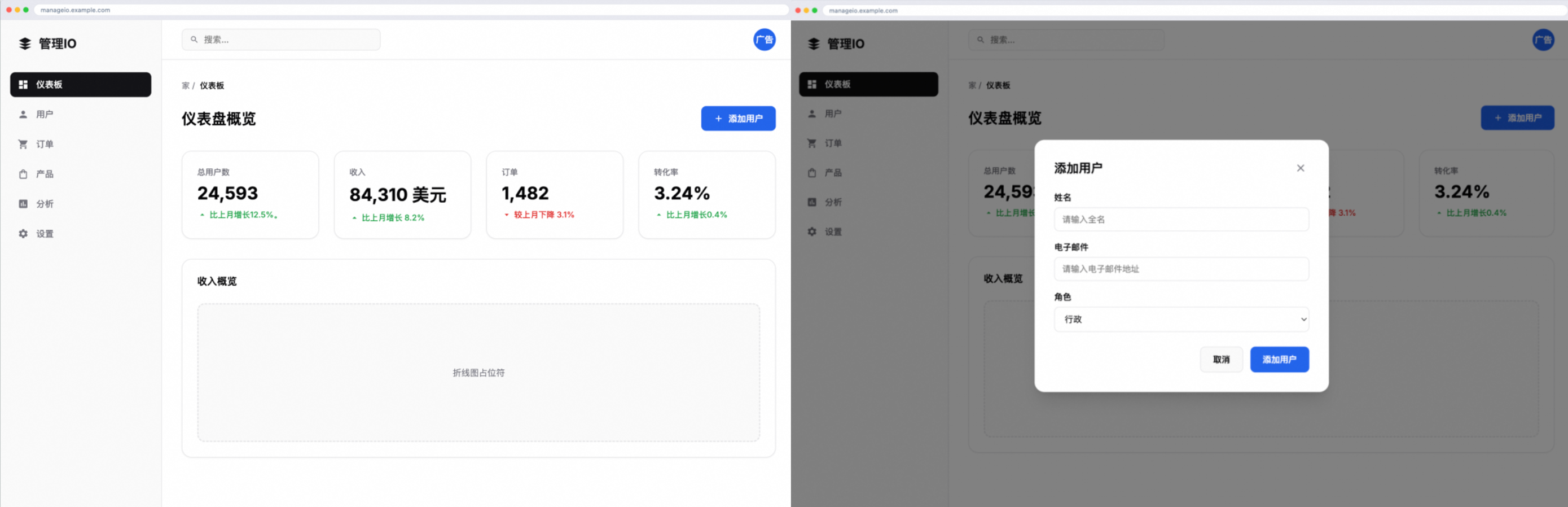
在博客中,阿里研究人员提到,他们希望探索基于语言模型的世界建模,能否进一步拓展通用智能体能力的边界。
第一个方向是构建智能体环境模拟的基础模型:Qwen-AgentWorld是首个在单一模型中覆盖七大智能体交互领域的语言世界模型,基于超过1000万条真实环境交互轨迹,经由CPT→SFT→RL三阶段训练而成。

▲三阶段训练流程
第二个方向是探讨世界建模在智能体训练中的作用,并通过两种互补范式加以验证:作为解耦的环境模拟器,它为智能体强化学习提供了更优的可扩展性与可控性,可控的模拟RL能够以真实环境无法实现的方式塑造智能体行为,且显著优于仅在真实环境中训练的RL。
作为统一的智能体基础模型,LWM的预训练可有效迁移至涵盖七个基准(其中三个完全未出现在训练集中)的多轮智能体任务,且无需针对智能体任务进行任何RL微调,初步验证了语言世界模型能够作为构建更强智能体模型的基础。
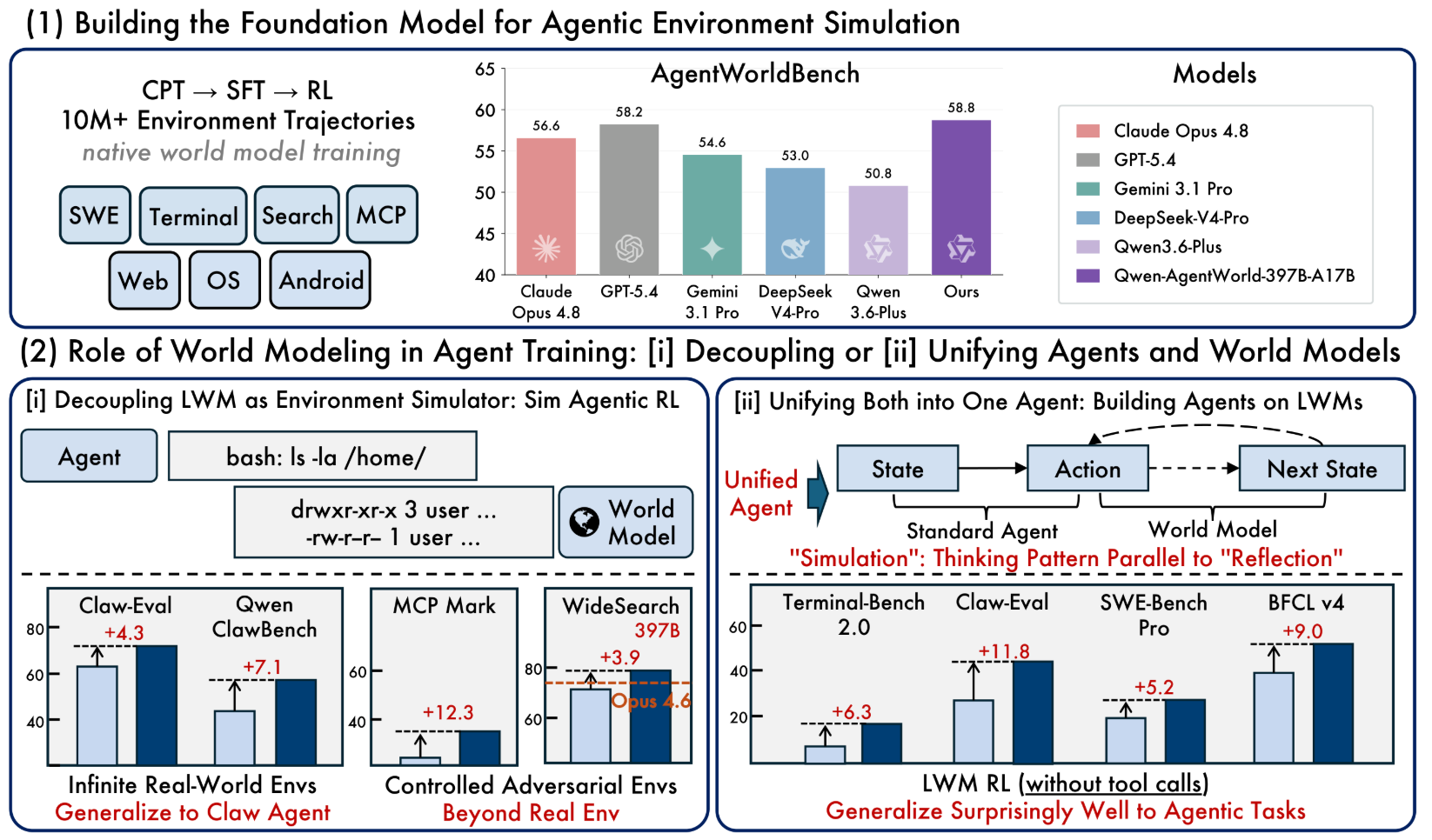
▲Qwen-AgentWorld架构图
二、整体模拟质量超Claude Opus 4.8、Gemini 3.1 Pro
为系统评估语言世界模型,研究人员推出综合性评测基准AgentWorldBench。
该基准基于5个前沿模型在9个成熟评测集上的真实环境交互观测构建而成。AgentWorldBench采用开放式评分准则(rubric),从格式、事实性、一致性、真实性和质量五个维度全面评估世界建模能力,深入考察模型的推理能力、领域知识以及长上下文处理水平。
在AgentWorldBench评测中,Qwen-AgentWorld-397B-A17B的整体模拟质量超越GPT-5.4、Claude Opus 4.8与Gemini 3.1 Pro。
Qwen-AgentWorld-397B-A17B在AgentWorldBench上取得最高的整体均分(58.71),超越GPT-5.4(58.25)及所有其他前沿模型。这一优势在Terminal和SWE两个领域最为显著,研究人员认为这是因为这两个领域的预测需要准确模拟代码执行状态和工具API行为。
在35B-A3B规模上,三阶段训练流水线将整体均分提升了8.66分,使Qwen-AgentWorld-35B-A3B的表现超过Claude Sonnet 4.6。这一提升在文本类和GUI类领域中均保持一致。
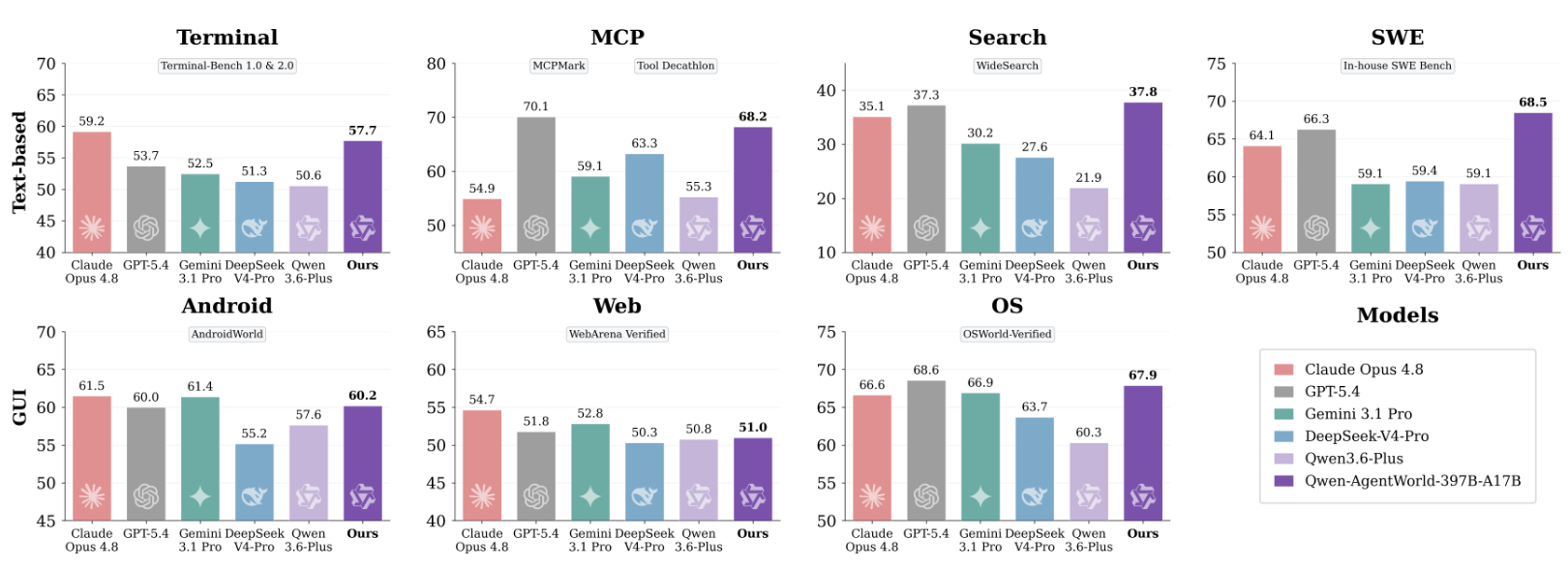
▲AgentWorldBench评测结果
三、涌现3种推理模式:自纠错、防信息泄露、多步因果推理
在整体分数的分析之外,研究人员还分析了4个文本类领域的129条思维链,发现3种涌现的推理模式。
自我修正:模型使用「Wait!」作为自我纠错的触发信号,以修正中间预测。在129个轮次中有1347次此类中断(平均每turn 10.4次),包括事实错误、知识边界或视角转换等情况。
信息泄漏防护:在搜索领域,模型已知智能体正在搜索的参考答案,当查询与答案无关时,模型通过确保摘要不会意外透露目标来防止泄漏。
多步因果推理:预测curl -s localhost:3000 | python3 -m json.tool的输出需要一条6步推理链:Node.js缺失→服务器未启动→端口3000无监听→curl静默失败→空管道→json.tool抛出JSONDecodeError。
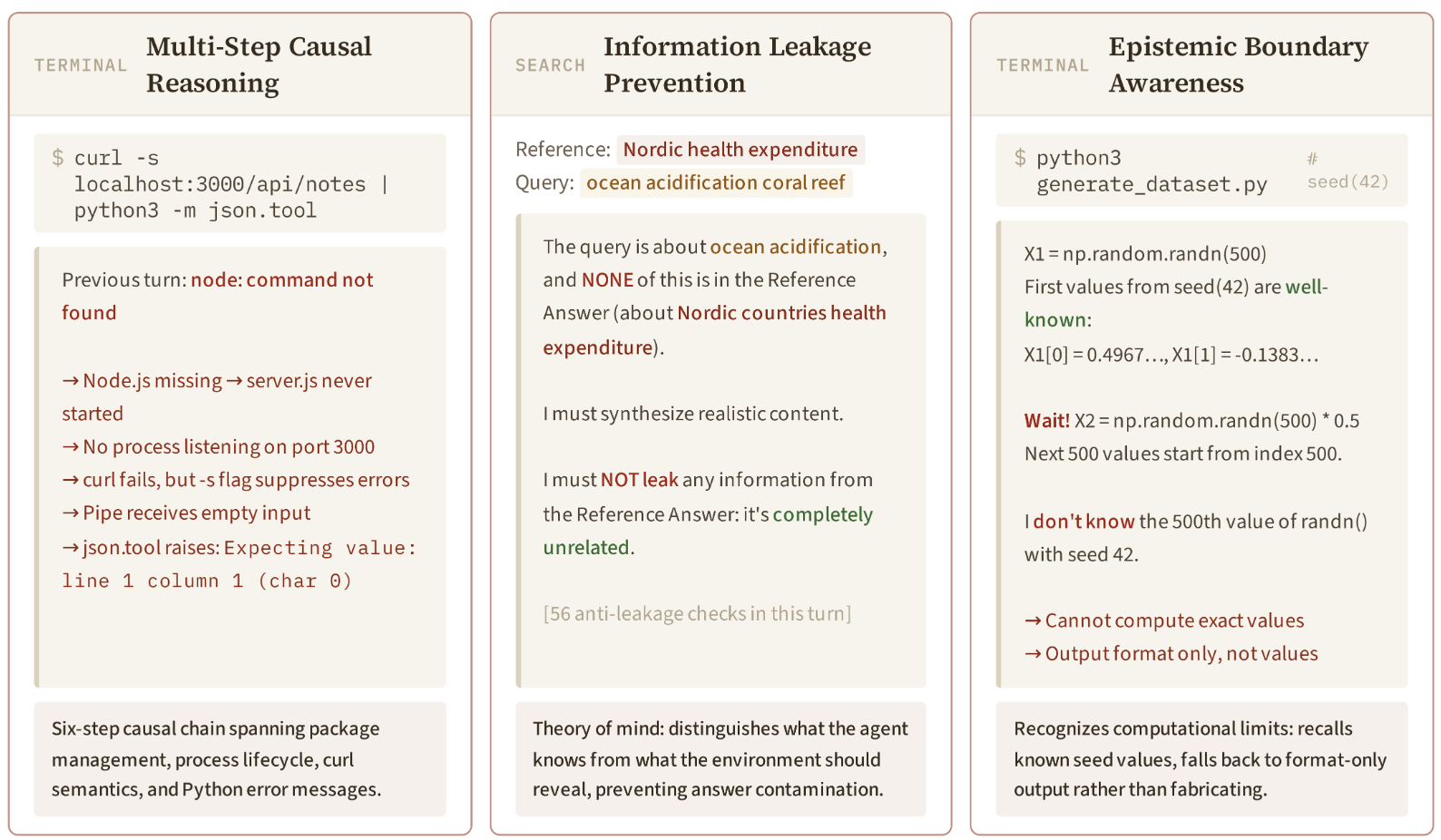
▲Qwen-AgentWorld的推理模式
结语:单一模型统一七大交互环境,语言世界建模或打开通用智能体新路径
Qwen-AgentWorld是一个原生语言世界模型,在单一模型中覆盖七大智能体交互领域,基于此研究人员探索了世界模型加强通用智能体的两种互补范式。
作为统一智能体基础模型,语言世界模型(LWM)的预训练可迁移至涵盖七个基准的多轮智能体任务,初步验证了语言世界模型能够作为构建更强智能体模型的基础。语言世界建模或开辟了一条互补的扩展路径,推动通用智能体超越真实环境交互的能力上限。